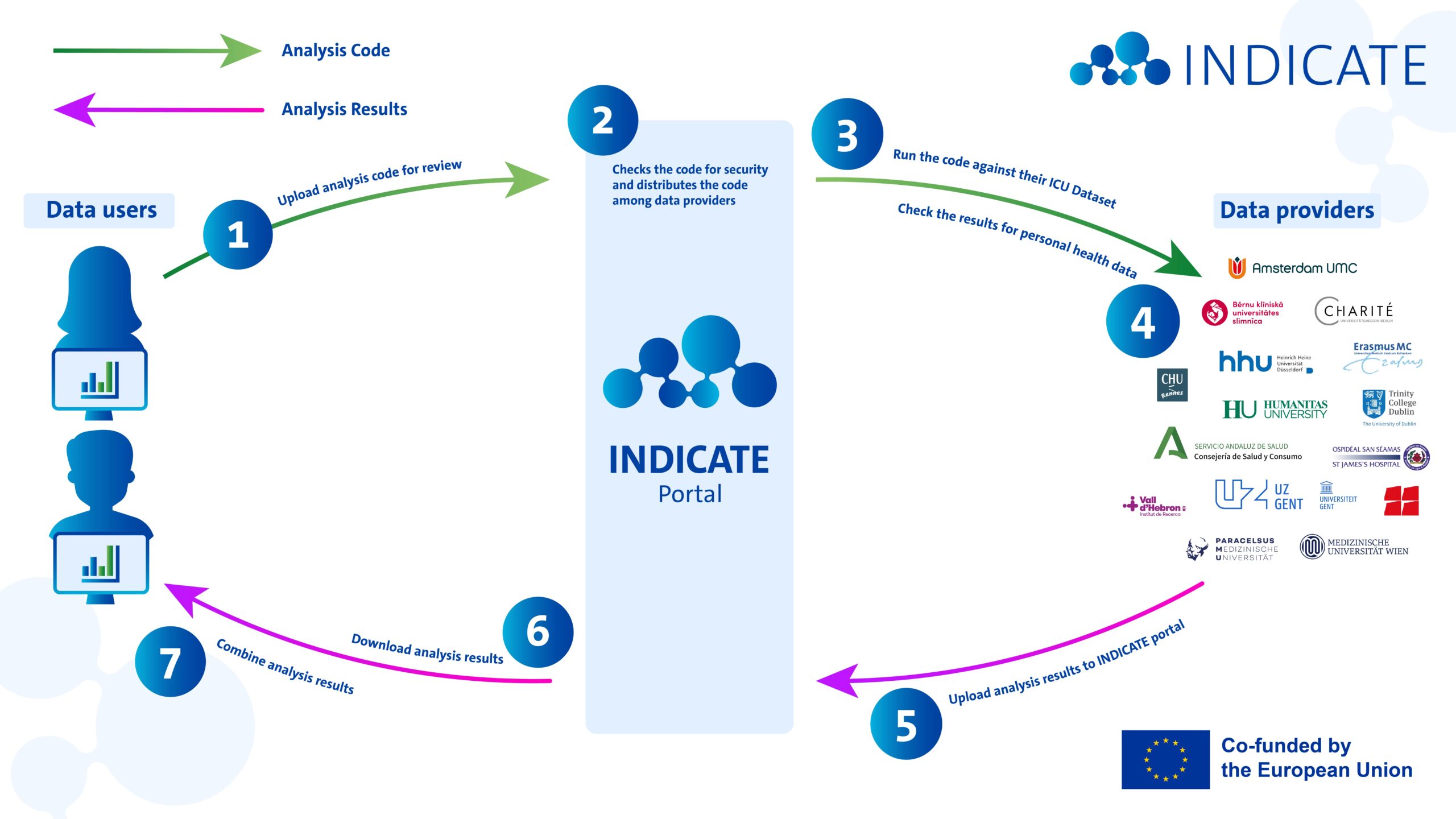
On Monday 25 May 2026, Boris Delange (MD, Medical Informatics & Intensive Care, University Hospital of Rennes), presented the INDICATE Minimal Data Dictionary to the European medical informatics community during MIE 2026 (Medical Informatics Europe), held in Genova, Italy (25-28 May 2026).
On behalf of the INDICATE consortium, Boris presented the INDICATE Minimal Data Dictionary. This is a carefully selected and peer-reviewed list of ICU concepts that is compatible with OMOP and FHIR. It helps clinicians and data scientists use the same language and makes the process of mapping concepts faster and easier. This is an important step for federated ICU research, where data can be used across different locations without being moved.
Boris started with a simple observation: clinicians and data scientists don’t speak the same language. A clinician asks for “total bilirubin”, while a data engineer needs the exact technical definition and the specific codes (LOINC, SNOMED CT, etc.). The INDICATE Data Dictionary provides both, side by side. Concept mapping is hard: a single variable can map to hundreds of candidate codes, so every data provider redoes the same work and often chooses differently – small inconsistencies that can silently bias federated analyses!
Boris presented the dictionary which contains 332 peer-reviewed, ETL-ready concept sets across 9 clinical categories, each linked to both OMOP and HL7 FHIR, using SNOMED CT, LOINC, RxNorm and UCUM. Every concept set is versioned, reviewed, and enriched with expert comments – and its quality comes from the diversity of reviewers: a pharmacist, a biologist, an intensivist each catch different issues.
The web application of INDICATE was also shared, this runs entirely in the browser with no install and no login: anyone can browse, search, read the expert comments, and suggest changes in a couple of clicks. It supports both OMOP and FHIR from the start, which is still rare.
The dictionary is also one of the building blocks of INDICATE’s federated infrastructure, which spans 15 data providers across 12 European countries and 6 clinical use cases.
The MIE is an event attended by researchers, clinicians, data scientists, informaticians and interoperability experts working on health data standardization and federated analytics across Europe – and anyone interested in OMOP/FHIR-based ICU data harmonization.
The INDICATE team from Seville was present as well – notably Carlos Luis Parra-Calderón. The work is a joint effort of the INDICATE Clinical Demonstrations and Common Data Models work packages.
How do we ensure that clinicians, researchers, nurses, legal experts, and data engineers have the knowledge, skills, and confidence needed to participate in federated health data research? Today, the INDICATE Training and Education Workgroup met at ESICM in Brussels to discuss one of the most important ingredients for successful federated data research: people.
What did we focus on in Brussels?
Define tailored learning pathways for different stakeholder groups
Develop educational onboarding journeys for both data providers and data users
Identify the skills, competencies, and support structures needed to enable effective participation in federated health data research
Some key takeaways?
Institutional readiness is just as important as individual readiness
Clinicians, nurses, researchers, legal experts, and data engineers all have a role to play
Education should be practical, interactive, and aligned with the stage of onboarding and implementation
Based on the outcomes of today’s discussions, we will further develop targeted onboarding courses, hands-on workshops, and role-specific learning opportunities.
A recurring theme throughout the meeting was simple: we are here to learn from each other. Thank you to all members of the Training and Education Workgroup for the valuable discussions, insights, and ideas. We look forward to translating these into practical educational pathways that will help make federated health data research a reality across Europe.
Jan van den Brand – Lisanne van Prooyen Schuurman – Marcel Giemsa – Maria Theodorakopoulou – Maarten Ligtenberg – Bert Cappelle – Maaike van Zuilen – Margo van Mol – Elisa Vera – Melania Istrate – Celia Alvarez Romero – Julie Benbenishty
On 21 May, the fourth INDICATE training session brought together participants from across the consortium to explore one of the most critical aspects of data integration: ensuring data quality throughout the ETL (Extract, Transform, Load) process.
Led by Celia Alvarez Romero and María González-Lopez from the Computational Health Informatics Group at Virgen del Rocío University Hospital, the training focused on practical approaches to data validation, quality assessment, and troubleshooting within the INDICATE data infrastructure.
Participants revisited the process of transforming intensive care data from different hospital systems into common standards that enable information to be shared and analysed consistently across institutions. The discussion highlighted that achieving this requires more than technical tools and data standards. It depends on close collaboration between clinicians, data experts, terminology specialists, and technical teams to ensure that clinical information is accurately represented and can be reused for research and innovation.
A major focus was on data quality assessment. Rather than discussing validation only from a theoretical perspective, participants followed the fictional journey of “Hospital A”, a European hospital preparing to join INDICATE as a data provider. After successfully completing its ETL process and creating a local OMOP instance, Hospital A began evaluating the quality of its transformed data.
Using a series of realistic scenarios, attendees explored common challenges such as missing data, incorrect units, mapping inconsistencies, and implausible values. Together, they discussed the most likely causes of these issues and identified practical solutions.
Participants also reviewed the results of a recent survey among INDICATE data providers across Europe. The findings of this survey are that many hospitals already have strong foundations in place for sharing and secondary use of intensive care data for research purposes. At the same time, the survey highlighted several common challenges, including limited staff capacity for data integration and ETL work, difficulties in achieving interoperability across different hospital systems, and varying levels of maturity in data quality management and validation processes.
One of the central takeaways was that data quality is not a one-time task but an ongoing, collaborative effort. Effective validation requires continuous communication between clinicians, data stewards, ETL developers, and technical experts to ensure that data remains accurate, complete, and fit for federated research and AI applications.
The INDICATE Training programme on Data Model & Data Enablement consists of five sessions. The next and last session will take place on June 17, 14:00–16:00 CEST.
We are excited to invite you to the official Consortium Meeting of the INDICATE project, taking place from 14 till 16 September 2026 in Rome, Italy. This meeting will be graciously hosted by our partner, Fondazione Policlinio Universitario Agostino Gemelli IRCCS.
Practical information Date: 14-16 September Location: Italy, Rome Venue: Fondazione Policlinico Universitario Agostino Gemelli IRCCS, Largo Agostino Gemelli 8, 00136 Roma, Italy
As we are in September 2026, approximately halfway through the project, this meeting will focus on reflection and forward planning. We will review key achievements, such as the first use case going live, as well as main challenges, including updates on communication and education.
Looking ahead, we will focus on the second half of the project. The session will zoom in on upcoming deliverables and milestones, progress on data provider onboarding, and the next steps in establishing the legal entity that will operate the infrastructure.
We hope you will join us in person in Rome. For those unable to travel, the program will also be accessible online via Microsoft Teams. A link for virtual participation will be shared closer to the event (please also register if you are attending online).
Prof. Christian Jung presents INDICATE at the 8th Critical Care Clinical Trialists Workshop
On 1–2 June 2026, Prof. Christian Jung, Coordinator of the INDICATE project, participated in the 8th Critical Care Clinical Trialists (3CT) Workshop in Washington, DC.
During the meeting, Prof. Jung delivered a presentation titled “The European Experience – from Registries to Research Questions”, highlighting how European registries and collaborative data infrastructures can be transformed into meaningful research questions and innovative clinical studies in critical care medicine.
Building the foundations for Federated Healthcare Research
On 7 May 2026, the INDICATE training session about the Extraction, Transformation and Load (ETL) process within the INDICATE project took place! The session was given by Celia Alvarez-Romero, María Parra Rodríguez-Armijo and María González-Lopez.
This training session helped participants better understand the INDICATE data architecture, including the dual Common Data Model (CDM) approach. Participants also learned more about the technical requirements, tools and skills needed to successfully implement ETL processes in their organisations.
Trust over rules and regulation: what really determines success in health data ecosystems
The first session of the INDICATE Training Programme on Legal Framework kicked off! These sessions are running in parallel with and complementing the ongoing Data Models sessions.
The first session, led by Ricard Martínez Martínez (Universitat de Valencia), explored how law, technology, and organisation together shape the use of health data in research. A key message was that rules are important, but it is not enough on its own. Trust and responsibility are just as important.
Towards a standard concept recommendation for Federated Intensive Care research: The INDICATE Data Dictionary
On April 20, Boris Delange (MD, Medical Informatics, Université de Rennes) presented the INDICATE Data Dictionary to the OHDSI community, during the OHDSI Symposium. He demonstrated through a live demo, how the data dictionary bridges the gap between clinicians and data scientists when working with medical concepts within the OMOP (Observational Medical Outcomes Partnership) framework.
The OMOP Common Data Model explained: speaking the language of health data
The second training of the INDICATE Training Programme on Interoperability, OMOP and Vocabularies took place on April 9, 2026. During this second training, led by Maxim Moinat (Researcher, Medical Informatics, Erasmus MC) and moderated by Boris Delange (MD, Medical Informatics, Université de Rennes), participants learned that data from different hospitals and institutions must be made interoperable to enable research at a European level.
INDICATE Training session on Onboarding & Data Model: Unlocking ICU data across Europe without moving patient data
The first session of the INDICATE Training Programme took place. The programme is designed to support data providers in using the INDICATE infrastructure effectively, securely, and in a fully standardized way.
Moving from Vision to Implementation in federated ICU Research
We’ve gathered in Brussels for the INDICATE Design Workshop – a two-day event bringing together hospitals, technical experts, clinicians and communication advisors from across Europe. INDICATE is building a federated data infrastructure for intensive care data. That means: collaborating on better care and research, without patient data ever leaving a single hospital.
INDICATE Round Table: Federated Infrastructures in Medical Research
On 5 March 2026, INDICATE hosted a hybrid round table in Düsseldorf, bringing together experts from across Europe for an active exchange between clinicians, researchers, and technical experts working on data-driven healthcare. The day was moderated by INDICATE PI’s Michel van Genderen from Erasmus MC and Christian Jung from Universitätsklinikum Düsseldorf.
Spotlight on INDICATE: Poster Presentation at Seville’s Researchers’ Forum!
On 5 March, Luis Martín-Villén (Head of ICU), Carlos Luis Parra-Calderón (Head of Technological Innovation), Celia Alvarez-Romero, María González-López, María Parra-Rodríguez-Armijo, Paloma Bravo-del-CID, and Paco Rey-Garduño (Computational Health Informatics Group) from Hospital Universitario Virgen del Rocío and part of the INDICATE consortium, presented an INDICATE poster at the XXII Researchers’ Forum, organised by the Institute of Biomedicine of Seville.
We are happy to invite you to a new series of the INDICATE Training Programme on Legal Framework.
The sessions, running in parallel with and complementing the ongoing Data Models sessions, will provide you a comprehensive understanding of the INDICATE legal framework, covering GDPR and EHDS principles, data protection and privacy-enhancing technologies, governance and rulebook structures, and practical skills to navigate data access processes, compliance requirements, and organizational implementation challenges within INDICATE.
The first session took place on May 4 and led by Ricard Martínez Martínez (Universitat de Valencia). He explored how law, technology, and organisation together shape the use of health data in research. A key message was that rules are important, but it is not enough on its own. Trust and responsibility are just as important! The recording of this session is added in sections to the INDICATE Education Platform.
Upcoming session dates All sessions will be held from 14.00 – 16.00 (CEST) via Zoom. Upcoming sessions:
June 24 – Session 2 | Understanding and using Data Access
September 10 – Session 3 | Understanding the Rulebook and legal onboarding steps
Data Protection Workgroup
We are currently looking for an additional member to join the Data Protection Workgroup.
The Data Protection Workgroup oversees the design and implementation of the project’s data management processes, ensuring strong data protection and privacy protocols. In addition, it will advise on compliance with the General Data Protection Regulation (GDPR) and other relevant national or European data protection laws.
Furthermore, the group will identify potential data security risks, propose mitigation strategies, and support the development of safe data-sharing infrastructures across European ICUs.
These deliverables represent significant progress in the development of INDICATE’s governance framework, data infrastructure, knowledge-sharing capabilities, and quality benchmarking services.
AP-HP Assistance publique – Hôpitaux de Paris, a valued partner for the INDICATE project, is seeking a highly motivated Statistician / Applied Mathematician / Data Scientist to contribute to the development and validation of predictive models of organ failure in critically ill patients. The position is part of the European INDICATE project and focuses on translational research at the interface between medicine, statistics, and artificial intelligence.
Strong background in statistics, applied mathematics, or data science
Experience in predictive modeling and machine learning
Programming skills: Python (mandatory), SQL; Java/C++ is a plus
Interest in biomedical applications and clinical data
Methodological Framework
The candidate will implement and validate advanced statistical and machine learning models, including supervised learning, time-series modeling, and trajectory analysis. Key aspects include feature engineering from high-frequency data, handling missing data, model calibration and discrimination assessment, and external validation when available.
Contract and Conditions
Fixed-term contract (18 months)
Full-time (100%)
Location: INSERM U942, Paris (AP-HP / Université Paris Cité)
English required; French not mandatory
To apply for this position, please send your CV and motivational letter to contact Dr. Benjamin Deniau via benjamin.deniau@aphp.fr and Ms. Fatima Zunara via fatima.zunara@aphp.fr.
We would like to invite you to join the upcoming online INDICATE Communication Network Meeting on September 9, 2026 from 12.30 – 13.30 CEST. This meeting is an important moment to reflect on how communication about INDICATE is currently being organised and shared within the different partner organisations.
Together, we would like to explore how we can strengthen our communication efforts, improve visibility and outreach, and support each other in sharing the project’s progress and impact more effectively. The meeting will also provide space for partners to ask questions, exchange ideas, share challenges, and discuss opportunities for collaboration regarding communication activities.
My name is Mark Driessen, Manager at KPMG Netherlands, based in Amstelveen. I started my professional career as a physical therapist, which gave me a strong grounding in clinical practice and the day‑to‑day realities of healthcare delivery.
After a period at the Royal Dutch Marines I continued my career in consultancy with a focus on digital strategy and healthcare transformation, where I now work at the intersection of care, data, and technology.
What do I do? In my current role, I advise healthcare organizations on digital strategy, data & AI, cloud transformation, and governance. I support organizations in translating strategic ambitions into practical, sustainable solutions, with a strong focus on collaboration between care providers, technology partners, and policymakers. My work combines strategic design with hands‑on implementation, always anchored in real healthcare needs.
Find out more about Mark’s contributions to INDICATE in his bio.
My name is Anouk Kruiswijk and I am a senior consultant at KPMG The Netherlands. I started my career as a PhD student at the Leiden University Medical Center where I worked at the intersection of clinical research and artificial intelligence.
After my PhD, I transitioned into consultancy, allowing me to combine academic research with real-world implementation and strategy. I very much enjoy working at the boundary of these two worlds!
What am I up to during INDICATE? Together with my colleague Mark van Driessen, I am responsible for Work Package 3 within INDICATE. In this role, we advise the project on how to set up a sustainable INDICATE ecosystem beyond the project phase. This includes designing the legal entity, developing governance structures, defining clear roles and responsibilities, shaping a viable business model, and outlining a realistic implementation roadmap. Our goal is to ensure that INDICATE can grow into a durable European infrastructure that continues to create value after the project ends.
Find out more about Anouk’s contributions to INDICATE in her bio.
My name is Marcel Giemsa, and I work as a Research Associate at the Department of Cardiology, Pulmonology and Angiology at the University Hospital Düsseldorf, in the group of Prof. Dr. Dr. med. Christian Jung.
I hold a Bachelor’s degree in Biology from Ruhr University Bochum, and this summer I will complete a second Bachelor’s degree in Computer Science at Heinrich Heine University Düsseldorf. I originally joined Christian’s group as a student assistant, and after some time he asked me whether I would like to take on a larger role within the team — which is how I ended up working on INDICATE.
What am I up to during INDICATE? Within INDICATE, I am responsible for the coordination of Work Package 6 and take on technical coordination tasks across the project. This includes a fair amount of hands-on project management, as well as supporting data analysis activities. A core part of my role is acting as a bridge between the clinical and the technical domains: translating clinical requirements into technical specifications, and making sure that the technical work stays aligned with the real-world needs of the ICUs and clinicians we serve. Because WP6 sits at the intersection of so many topics, a lot of my day-to-day work is about keeping the different threads connected and making sure information flows between the people who need it.
Find out more about Marcel’s contributions to INDICATE in his bio.
Do you have a special request? Would you like to share news or a publication? Would you like to be (digitally) connected to a certain person? Did you speak or went to an event related to INDICATE or INDICATE-subjects? Please feel very welcome to share your questions or input with: info@indicate-europe.eu
When sharing your news, please make sure to attach your photos/images or figures and always make sure when people are visible, you have their permission to use the pictures.
Below with the format you can use to share your news with us:
What is the purpose of your news?
What title can we use?
Who attended (names, roles, if related to INDICATE meetings/events)?
What were the main topics discussed or key findings?
Were any follow-up actions or appointments agreed upon?
All data elements for the use cases (WP6) are defined (SAS)
WP6 | MS18
Public release of the MIMIC-EU federated database (UDUS)
All consortium partners can access the official presentation templates and branding materials for INDICATE via the INDICATE Wiki. There you can find the PowerPoint template, Word template, Teams background, logo files, branding guidelines, and icons. Everything you need to ensure consistent and professional project communication.
On 1–2 June 2026, Prof. Christian Jung, Coordinator of the INDICATE project, participated in the 8th Critical Care Clinical Trialists (3CT) Workshop in Washington, DC.
During the meeting, Prof. Jung delivered a presentation titled “The European Experience – from Registries to Research Questions”, highlighting how European registries and collaborative data infrastructures can be transformed into meaningful research questions and innovative clinical studies in critical care medicine.
As part of his presentation, Prof. Jung shared insights from the INDICATE project, which is building a European federated data infrastructure to support research and innovation in intensive care. He discussed how high-quality clinical data, interoperability, and trustworthy artificial intelligence can help accelerate research, generate new evidence, and improve outcomes for critically ill patients across Europe. The presentation also highlighted INDICATE’s work in enabling cross-border collaboration through federated data access, allowing researchers to answer important clinical questions while ensuring that patient data remain secure and locally governed.
The annual 3CT Workshop brings together leading international experts in critical care, cardiovascular medicine, pulmonology, emergency medicine, clinical trial design, industry, and regulatory agencies to discuss advances in clinical research and the future of critical care trials.
On 7 May 2026, the INDICATE training session about the Extraction, Transformation and Load (ETL) process within the INDICATE project took place! The session was given by Celia Alvarez-Romero, María Parra Rodríguez-Armijo and María González-Lopez.
The programme is designed to support data providers in the implementation of ETL processes and in following the Common Data Model (CDM) within the INDICATE infrastructure effectively, securely, and in a fully standardised way. It helps participants, such as clinicians and data engineers, build both the conceptual understanding and practical skills needed to work with interoperable health data.
This training session helped participants better understand the INDICATE data architecture, including the dual Common Data Model (CDM) approach. Participants also learned more about the technical requirements, tools and skills needed to successfully implement ETL processes in their organisations.
During the session, the importance of good data preparation was explained. Before starting the ETL process, healthcare data must be organised, checked and prepared correctly. The Data Provider Handbook supports organisations with practical guidance and explains the minimum technical and procedural requirements needed to transform local intensive care data into the OMOP Common Data Model (OMOP CDM).
The session also explained how the federated approach in INDICATE works. Data stays safely stored at each hospital or organisation and is not transferred to a central database. This helps protect patient privacy and supports secure collaboration between partners across Europe.
Participants also followed the INDICATE data workflow from local ICU source systems to data ready for federated use. The session explained how information from clinical environments can be identified, extracted, transformed through ETL logic, loaded into a local OMOP CDM instance and checked before analysis. HL7 FHIR was presented only as an optional support layer for structured access or interoperability when available or useful, while the main transformation pathway focuses on preparing local ICU data in OMOP CDM. The workflow also highlighted the importance of the local environment, where execution, semantic alignment, validation and governance controls come together before data can support distributed analyses.
The ETL tooling section showed how this workflow can be translated into practical implementation steps for Data Providers. These steps include confirming local readiness, profiling source data, defining mappings, implementing transformation logic, loading the local OMOP CDM, running quality checks and refining the process when issues are detected. The tools were presented as part of an iterative workflow rather than isolated components, supporting profiling, mapping, vocabulary alignment, implementation and post-load validation. This helped clarify how INDICATE moves from architecture to execution, turning complex ICU data into reliable, comparable and analysis-ready resources.
The INDICATE Training programme on Data Model & Data Enablement consists of five sessions. The next and last session will take place on June 17, 14:00–16:00 CEST.